Stable Diffusion Guide For Begineers


What is Stable Diffusion?
Stable Diffusion is a deep learning, text-to-image model released in 2022 based on diffusion techniques which is capable of producing images from text and image prompts.
It is primarily used to generate detailed images by giving conditioned on text descriptions, though it can also be applied to other tasks such as inpainting, outpainting, and generating image-to-image translations guided by a text prompt. It was developed by researchers from the CompVis Group and Runway with a compute donation by Stability AI.
Why is Stable Diffusion important?
Stable Diffusion significantly reduces processing requirements and offers accessibility and convenience as it can be run on consumer-grade graphics cards, allowing anyone to easily download the model and generate their own images.
Moreover, users have the ability to control essential hyperparameters, such as the number of denoising steps and the degree of noise applied, adding to the flexibility of the technology.
It is under the Creative ML OpenRAIL-M license, allowing users to modify, use and redistribute the software as they see fit. If they release a derivative software based on this platform, they must follow the same license and provide a copy of the original Stable Diffusion license.
How does Stable Diffusion work?
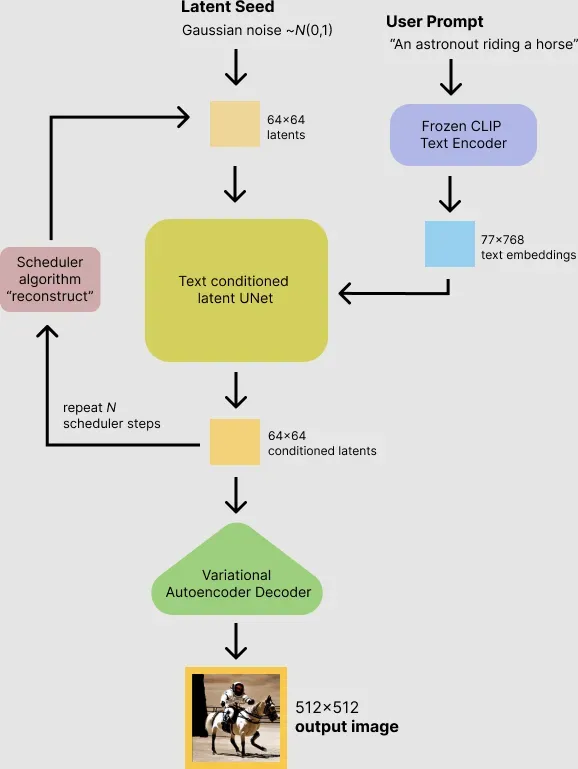
Apart from having the technical differences of a diffusion model, Stable Diffusion is unique in that it doesn't use the pixel space of the image. Instead, it uses a reduced-definition latent space. The reason for this is that a color image with 512x512 resolution has 786,432 possible values. By comparison, Stable Diffusion uses a compressed image that is 48 times smaller at 16,384 values. This significantly reduces processing requirements. And it's why you can use Stable Diffusion on a desktop with an NVIDIA GPU with 8 GB of RAM. The smaller latent space works because natural images aren't random. Stable Diffusion uses variational autoencoder (VAE) files in the decoder to paint fine details like eyes.
The Stable Diffusion model was initially trained on the laion2B-en and laion-high-resolution subsets, with the last few rounds of training done on LAION-Aesthetics v2 5+, a subset of 600 million captioned images which the LAION-Aesthetics Predictor V2 predicted that humans would, on average, give a score of at least 5 out of 10 when asked to rate how much they liked them.
The model was trained using 256 Nvidia A100 GPUs on AWS for a total of 150,000 GPU-hours, at a cost of $600,000.
Main Components Stable Diffusion use
VAE: Variational autoencoder
VAE consists of a separate encoder and decoder. The encoder compresses the 512x512 pixel image into a smaller 64x64 model in latent space that's easier to manipulate. Then the decoder restores the model from latent space into a full-size 512x512 pixel image.
U-Net: Noise predictor
A noise predictor is key for denoising images. Stable Diffusion uses a U-Net model to perform this. The noise predictor estimates the amount of noise in the latent space and subtracts this from the image. It repeats this process a specified number of times, reducing noise according to user-specified steps.
Text encoder
The most common form of conditioning is text prompts. A CLIP tokenizer analyzes each word in a textual prompt and embeds this data into a 768-value vector. You can use up to 75 tokens in a prompt. Stable Diffusion feeds these prompts from the text encoder to the U-Net noise predictor using a text transformer. By setting the seed to a random number generator, you can generate different images in the latent space.
What can Stable Diffusion do?
Text-to-image
Generating images through a text prompt is the most common way to use Stable Diffusion. You can adjust the seed number for the random generator or alter the denoising schedule to produce unique images with varying effects.
Image-to-image
Using an input image and text prompt, you can create images based on an input image.
By making use of an input image and input text prompt, it is possible to create images that are generated based on the given input image.
Video creation
2023-11-21, stability.ai released Stable Video Diffuson, the first foundation model for generative video based on the image model Stable Diffusion and it represents a significant step toward creaing models for everyone of every type.
How can we use Stable Diffusion?
You can download and install the Stable Diffusion WebUI to use SD and create your own images.
Later on, I will provide relevant installation and usage tutorials.