SDXL-Stable Diffusion XL


Stable Diffusion XL (SDXL) is a powerful text-to-image generation model.
Compared to Stable Diffusion V1 and V2, Stable Diffusion XL has made the following optimizations:
- Improvements have been made to the U-Net, VAE, and CLIP Text Encoder components of Stable Diffusion. The UNext is 3x larger.
- A separate Refiner model based on Latent has been added to improve the refinement of images.
- Many training tricks have been developed, including image size conditioning strategies, image crop parameter conditioning, and multi-scale training.





What is SDXL
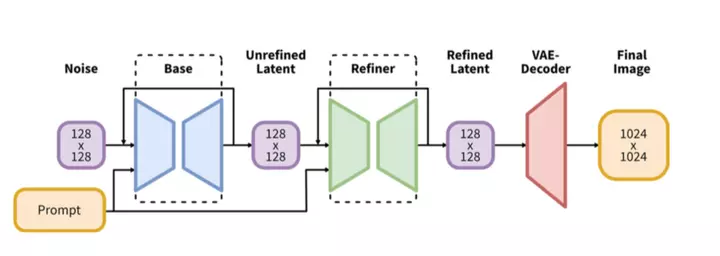
Stable Diffusion XL consisting of a Base model and a Refiner model. The main work of the Base model is consistent with that of Stable Diffusion, with the ability to perform text-to-image, image-to-image, and image inpainting.
The Base model consists of three modules: U-Net, VAE, and two CLIP Text Encoders. At FP16 precision, the size of the Base model is 6.94G (13.88G at FP32).
The Refiner model also consists of three modules: U-Net, VAE, and CLIP Text Encoder (one). The Refiner model size is 6.08G at FP16 accuracy.
Compared to Stable Diffusion, the parameter count of Stable Diffusion XL has increased to 6.6 billion (Base model: 3.5 billion; Refiner model: 3.1 billion). Additionally, two versions with identical model structures, 0.9 and 1.0, have been released. Stable Diffusion XL 1.0 uses a larger training set and RLHF to optimize the color, contrast, lighting, and shadow aspects of generated images, resulting in a more vivid and accurate composition than version 0.9.

Where can I download SDXL?
Here are the download links for the SDXL model
How to Use SDXL Model?
By default, SDXL generates a 1024x1024 image for the best results. You can try setting the height and width parameters to 768x768 or 512x512, but anything below 512x512 is not likely to work.
SDXL includes a refiner model specialized in denoising low-noise stage images to generate higher-quality images from the base model. There are two ways to use the refiner:
- use the base and refiner models together to produce a refined image
- use the base model to produce an image, and subsequently use the refiner model to add more details to the image (this is how SDXL was originally trained)
SDXL brings a significant improvement in the quality of images. Here are some examples.

Prompt
Astronaut on Mars, space suit with visible wear and tear marks, 4k
negative prompt
NA
Parameters
Sampling steps: 20
Image size: 768 x 768
Clip skip: 1
Sampling method: DPM++ 2M Karas
Model: SDXL V1.0 refiner
Seed: 125290976